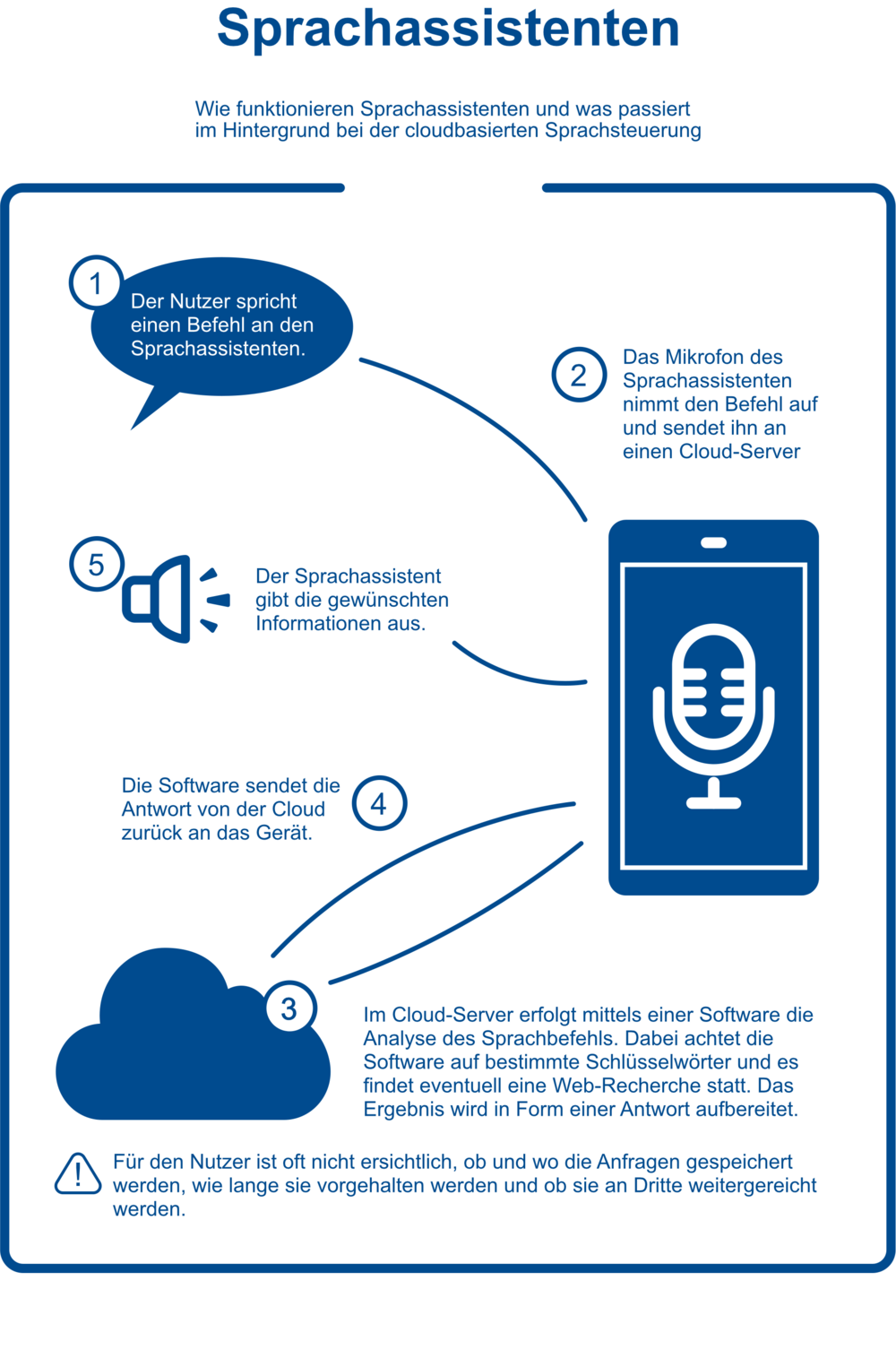
Wie funktionieren Sprachassistenten?
Immer mehr Menschen lassen sich in ihrem Alltag von Sprachassistenten unterstützen. Geräte wie Siri, Alexa oder der Google Assistant erleben gerade einen steigenden Beliebtheitsgrad. Ihre Anwendungsgebiete sind vielfältig, sie können Fragen zum Wetter beantworten, das Geschehen auf der Welt kommentieren, einen Witz erzählen oder Smart Home Geräte steuern. Doch wie funktionieren Sprachassistenten eigentlich? Und warum können Sprachassistenten auf unser Gesprochenes reagieren und verstehen, was wir sagen? Hier auf unsrer Trainingsplattform werfen wir einen Blick hinter die Kulissen eines Sprachassistenten.
Grundlegend verläuft die Verarbeitung von Sprachbefehlen in fünf Schritten: 1. Zuhören, 2. Aufwachen, 3. Verstehen, 4. Ausführen und 5. Sprechen. Im Folgenden wird jeder Schritt einzeln betrachtet und genauer erläutert.
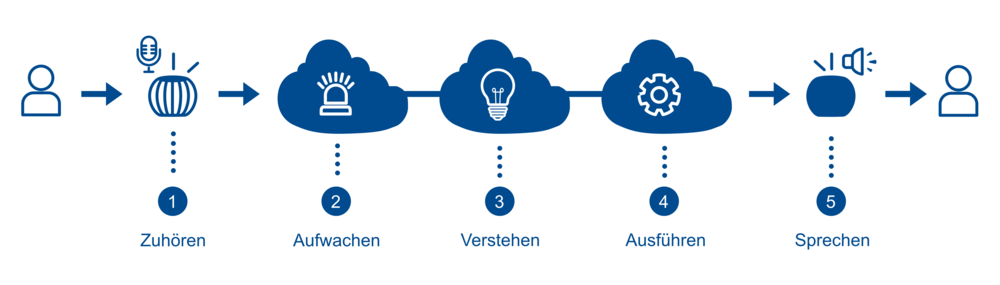
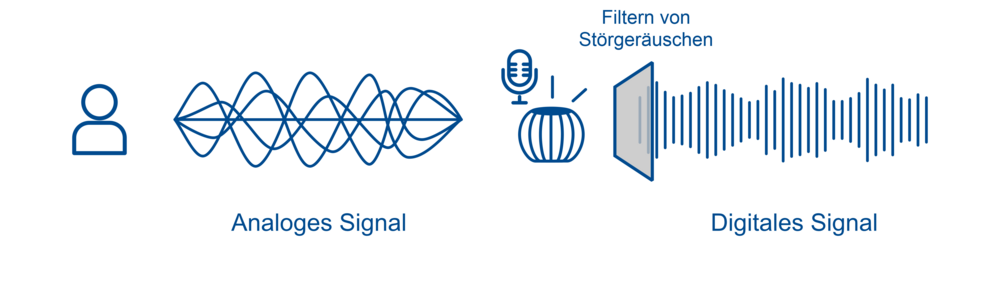
Schritt 1: Zuhören
Der erste Schritt ,,Zuhören‘‘ beginnt mit dem Erkennen von Stimmen aus der Umgebung über ein Mikrofon, welches standardgemäß in Smart Speakern verbaut ist. Die Mikrofone sind ständig aktiv und nehmen alle Audiosignale in Reichweite um sich herum wahr – jedoch ohne diese zu analysieren oder sie ins Internet zu senden. Der Sprachassistent hört dauerhaft zu, um seinen Einsatz nicht zu verpassen, wenn das Aktivierungswort fällt. Ist das nicht gewünscht, gibt es eine Taste, mit der das Mikrofon ausgeschaltet werden kann. Audiosignale allein reichen dem Smart Speaker nicht, deshalb wird das aufgenommene Audiosignal in ein digitales Signal umgewandelt. Störgeräusche werden aus dem aufgezeichneten Sprachbefehl herausgefiltert, um die Stimme der benutzenden Person zu isolieren und möglichst eindeutig zu verstehen.
Schritt 2: Aufwachen
Smart Speaker nehmen alle Audiosignale in ihrer Umgebung wahr, warten allerdings auf das sogenannte Aktivierungswort oder Wake-Word (z.B. „Okay-Google‘‘, „Alexa“). Erst wenn dieses Wort gefallen ist, wird das Gesagte aufgezeichnet und ins Internet gestreamt. Und um möglichst akkurat reagieren zu können, bezieht der Sprachassistent auch einige Sekunden des Gesagten mit ein, das vor dem Aktivierungswort gefallen ist.
Die aufgenommenen Schallwellen der Spracheingabe werden auf der Cloud des Anbieters (z.B. Amazon, Google, Apple) gespeichert. Der Smart Speaker benötigt dafür eine Internetverbindung, da bis auf das Aktivierungswort keine Audiosignale lokal verarbeitet werden. Neben dem Gesprochenen landen auch Metadaten in der Cloud. Darunter fällt z.B. die Uhrzeit, IP-Adresse, ggf. auf den Standort. Die Übertragung endet mit der Antwort des Geräts oder einige Sekunden danach.

Schritt 3: Verstehen
Wenn die Spracheingabe die Cloud des Anbieters erreicht, wird serverseitig geprüft, ob das Aktivierungswort tatsächlich gefallen ist, um unerwünschte Aktivierungen einzuschränken. Wurde das Aktivierungswort erfolgreich erkannt, geht es darum die aufgezeichnete Spracheingabe zu verstehen, wozu die gesprochene Sprache vom Sprachassistenten als erstes identifiziert und anschließend in maschinenlesbare Informationen umgewandelt werden muss. Unterschiedliche Abläufe im Bereich des Natural Language Processing (NLP) - also der Verarbeitung der natürlichen Sprache – sind hierfür notwendig.
Unter dem Natural Language Processing wird ein Teilgebiet der Informatik verstanden, welches sich mit der sinnvollen Textverarbeitung und Textanalyse einer Maschine beschäftigt. Mit NLP bei Sprachassistenten wird das Gesagte erkannt sowie die kontextuelle Bedeutung erfasst. Zudem ermöglicht NLP, Schlüsse aus dem Gesprochenen zu ziehen woraufhin der Sprachassistent Antworten, Reaktionen oder Aktionen generiert, die für den Nutzenden verständlich sind.
Spracherkennung (Automatic Speech Recognition – „Speech to Text“) – Was sagt der Nutzer?
Spracherkennung oder auch Automatic Speech Recognition (“Speech to Text”) dient dazu herauszufinden, was genau die Nutzenden sagen. Zuerst ist es wichtig zu wissen, dass aneinandergereihte Tonsequenzen der Bestandteil von gesprochener Sprache sind. Diese aneinandergereihten Tonsequenzen aus dem digitalen Audiosignal, welches bei den Sprachassistenten ankommt, werden zuerst in Frequenzen zerlegt und anschließend in einem Spektrogramm abgebildet. Unter einem Spektrogramm ist ein zeitlicher Verlauf in Form eines Diagramms zu verstehen, in dem Schalleigenschaften von Sprachelementen (Konsonanten, Vokale, etc.) erkennbar sind. Die Schallwellen und Tonsignale der gesprochenen Sprache werden in Echtzeit über Machine Learning Modelle auf Servern der Anbieter in lesbaren Text übersetzt. Auf Basis der transkribierten Spracheingabe wird die Wahrscheinlichkeit berechnet, warum die nutzende Person die Anfrage gestellt hat.
Jedoch kommt hier das Hindernis auf, dass sich aufgezeichnete Audiofiles untereinander unterscheiden, obwohl eigentlich das gleiche Wort gemeint ist. Der Grund hierfür: Jeder Mensch spricht anders. Zudem gibt es Wörter, wie beispielsweise “Mahl” und “Mal”, die vom Klang her identisch sind, jedoch etwas ganz anderes bedeuten.
Sprachverstehen (Natural Language Understanding) – Was meint der Nutzer?
Sprachverstehen oder auch Natural Language Understanding dient dazu herauszufinden, was genau die Nutzenden meinen. Nach den Prozessen der Spracherkennung werden Sprachbefehle der Nutzenden in Form von Text in einzelne semantische und grammatikalische Bausteine gegliedert. Dies geschieht durch Hinzuziehen eines Natural Language Understanding Systems (kurz: NLU-System). Durch die Zerlegung der transkribierten Sprachbefehle werden Rückschlüsse über die Bedeutung der gestellten Anfrage möglich.
Wenn eine Verarbeitung erfolgreich war, wurde die Absicht der Nutzenden (= Intent) festgestellt, zudem auch die zur Absicht zugehörigen Parameter (= Entitäten).
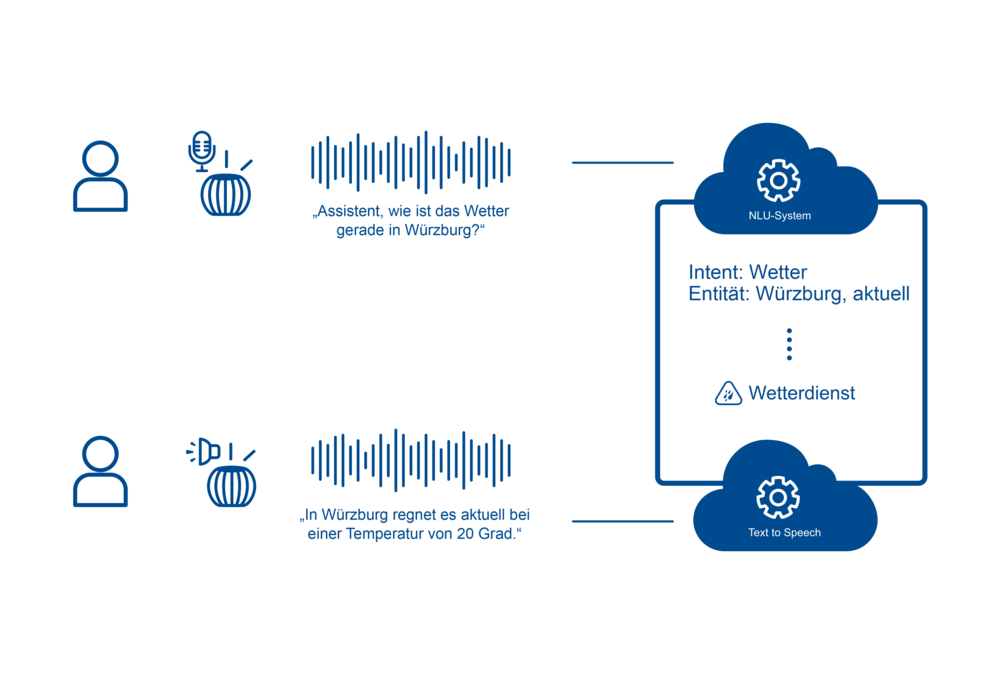
Zum Beispiel: „Alexa, wie ist aktuell das Wetter in Würzburg?“
Bei einer erfolgreichen Verarbeitung wird bei dieser Anfrage erkannt, dass die nutzende Person herausfinden will, wie das Wetter ist (= Intent). Die zugehörigen Parameter stellen hier die Stadt (= „Würzburg“ als Entität) und der Zeitraum (= „aktuell“ als Entität) dar.
Schritt 4: Ausführen
Für ein besseres Verständnis, wie eine Bearbeitung der Anfrage funktioniert, wird im Folgenden das eben aufgeführte Beispiel aufgegriffen: „Alexa, wie ist aktuell das Wetter in Würzburg?“.
Um die Anfrage zu bearbeiten, greift der Sprachassistent auf eine Wetterdatenbank zu. Das Gerät übermittelt die gesammelten Informationen “Wetter / aktuell / Würzburg” an die Wetterdatenbank. Werden dort die gesuchten Informationen gefunden, werden sie an den Sprachassistenten zurückgespielt, wodurch die Antwort auf den Sprachbefehl entsteht.
Verschiedene Aspekte beeinflussen, wie gut eine Absicht (= Intent) identifiziert wurde und daraufhin eine Antwort erstellt wird. Hierzu zählen beispielsweise Trainingsdaten oder Unternehmensdaten. Damit Sprachassistenten in ihrer Spracherkennung in Zukunft verbessert werden können, dienen sprachliche Aufzeichnungen von Nutzenden als Trainingsdaten und als Datenbasis für das Machine Learning.
Schritt 5: Sprechen
Spracherzeugung (Text to Speech)
Der fünfte und letzte Schritt dreht sich rund um die Spracherzeugung, was auch als „Text to Speech“ bezeichnet wird. Die erforderlichen Informationen für die Anfrage der Nutzenden liegen bislang ausschließlich in maschinenlesbarer Form vor. Folglich muss die Antwort des Sprachassistenten in eine für Menschen verständliche Form umgewandelt werden. Dies funktioniert durch sogenannte „Text to Speech Modelle“. Dabei werden die gesammelten Informationen zu den Anfragen der Nutzenden, von textbasierten computergenerierten Antworten in für den Menschen verständliche Sprache umgewandelt und weitergegeben.
Doch wie genau funktioniert Text to Speech eigentlich? Ein Sprachsynthesizer reiht Tonsequenzen oder ganze Wörter werden aneinander und verknüpft Tonsignale mit den passenden Klangeigenschaften von Vokalen, Konsonanten oder Wörtern. Im Anschluss wird die akustische Sprachausgabe in ein digitales Signal umgewandelt und über die Server an die Lautsprecher des Smart Speakers gesendet. Hierdurch wird das digitale Sprachsignal in ein hörbares Signal verwandelt. Die Folge: Die Nutzenden hören die Antwort des Sprachassistenten auf ihre gestellten Anfragen.
In Bezug auf das oben genannte Beispiel, ist eine mögliche Antwort: „In Würzburg scheint derzeit die Sonne bei 20 Grad“.
Zusammenfassung
Kurze Zusammenfassung darüber, wie Sprachassistenten die menschliche Sprache verstehen, diese verarbeiten und darauf reagieren:
- Sprachassistenten lauschen den Umgebungsgeräuschen und Warten auf das Aktivierungswort/Wake-Word (z. B. “Alexa” oder “Hey Google”).
- Das nach dem Aktivierungswort Gesagte wird an die Cloud gesendet und damit zur eigentlichen Software von Sprachassistenten übertragen.
- Das übermittelte Audiosignal in Form des Sprachbefehls wird in Text übersetzt, erkannt und verstanden (Speech to Text).
- Mittels Natural Language Understanding (NLU) wird die Absicht hinter dem Sprachbefehl erkannt.
- Der gestellte Sprachbefehl wird entweder durch den Sprachassistenten selbst oder durch eine externe Online-Datenbank bearbeitet.
- Eine Antwort auf die gestellte Anfrage wird erzeugt (Text to Speech) und ein Text, der die Antwort enthält, wird durch den Sprachassistenten an die nutzende Person zurückgegeben.
Im Bereich der Spracherkennungstechnologien gibt es aufgrund unterschiedlicher Faktoren immer noch hohe Fehlerraten. Gerade unsere sprachliche Vielfalt oder Soziolekte zeigen immer wieder, dass noch Verbesserungs- und Entwicklungsbedarf besteht. Jedoch kann schon jetzt gesagt werden, dass in der Zukunft große Fortschritte und Entwicklungen zu erwarten sind, da sich die Technologie rapide weiterentwickelt. Vor allem bessere Algorithmen der Audioverarbeitung oder neue Erkenntnisse im Machine Learning kündigen die Fortschritte und die damit einhergehenden Verbesserungen im Bereich der Spracherkennungstechnologien an.